


VI. Diagramme ERD▲
VI-A. Création d'une table▲
J'ajoute une nouvelle entité et directement j'ouvre la fenêtre de modification (clique droit, "Edit entity" ou simplement un double clique sur la table).
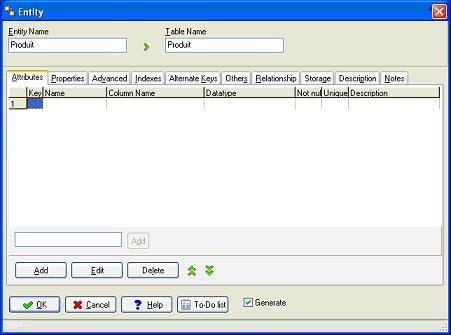
Nous sommes maintenant dans la fenêtre permettant de définir une table.
Pour définir les champs d'une table, il suffit d'ajouter des attributs via le bouton "Add". Les boutons "Edit" et "Delete" permettent respectivement de modifier et de supprimer l'attribut sélectionné.
Nous allons commencer par ajouter la référence du produit. Je choisis ici une référence numérique automatique.
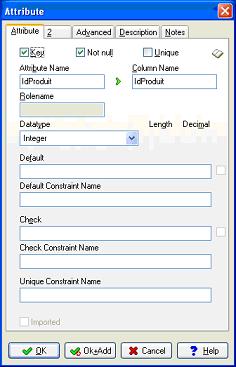
Notez au passage qu'il suffit de choisir "key" pour ajouter le champ à la clé primaire.
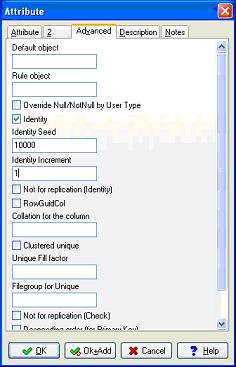
Dans l'onglet "Advanced", nous pouvons définir que le champ est de type "Identity" (autonumber). Le contenu de l'onglet "Advanced" dépend du gestionnaire de base de données précédemment choisi. L'onglet "description" défini le commentaire associé qui sera inscrit dans la base de données alors que l'onglet "Note" permet d'ajouter des informations destinées uniquement aux utilisateurs de Case studio.
Bien que nous soyons sur le troisième onglet, le fait de faire "Ok+Add" nous restitue une fenêtre vierge correctement positionnée sur l'onglet "Attribute". Si cela semble trivial, ce n'est pourtant pas toujours le cas. En revanche, j'aurai apprécié un système permettant de dupliquer la définition d'un champ pour les tables contenant un grand nombre de champs similaires si ce n'est le nom.
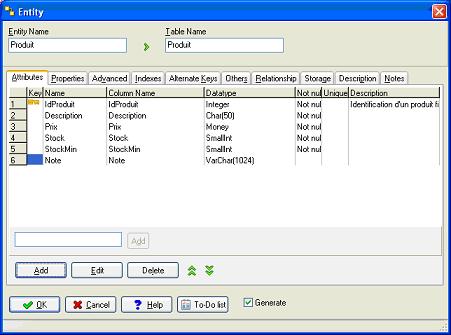
Comme vous pouvez le voir, la structure définie est clairement présentée dans la fenêtre.
La table (Entity) est maintenant affichée sur le bureau. Seul la clé primaire définie est représentée. En fait, il existe 4 modes d'affichage différents auxquels il faut encore ajouter les options "Physical view" et "Display index".
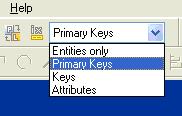
Notre modèle étant simple, nous pouvons nous permettre de choisir en permanence l'affichage le plus détaillé. Je choisis donc "Attributes" et "Physical view". A ce stade, "Display index" n'apporte rien mais vous pouvez aussi le sélectionner.
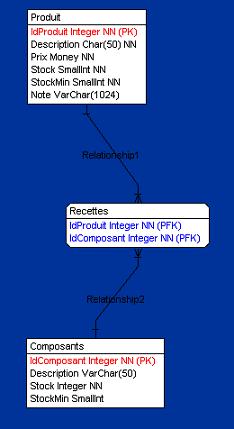
Après l'ajout des tables "Composants" et "Recettes", notre diagramme se présente comme ceci :

Vous remarquerez que la table Recettes est actuellement vide.
VI-B. Création des relations▲
Avec l'icône
![]() de la barre d'outils, je crée une relation
identifiée de "Produits" vers "Recettes" et une de "Composants"
vers "Recettes". La clé primaire, grâce au choix d'une relation
identifiée, et les clés étrangères sont automatiquement créées.
Les champs nécessaires sont ajoutés dans la table "Recettes".
de la barre d'outils, je crée une relation
identifiée de "Produits" vers "Recettes" et une de "Composants"
vers "Recettes". La clé primaire, grâce au choix d'une relation
identifiée, et les clés étrangères sont automatiquement créées.
Les champs nécessaires sont ajoutés dans la table "Recettes".
En double cliquant sur une relation, nous obtenons les propriétés de celle-ci.
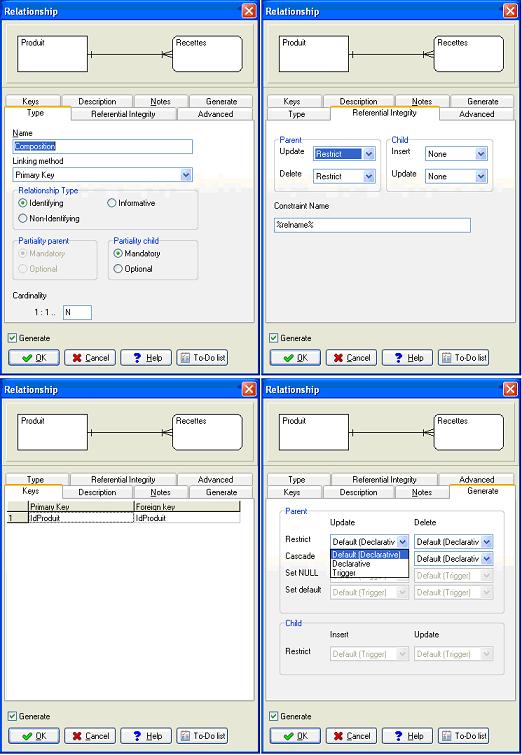
Il est alors possible de modifier finement la relation. Vous pouvez ainsi insérer 4 types de relations :
- Identifiée, la clé primaire migre vers la table enfant et participe à sa clé primaire.
- Non identifiée, la clé primaire migre vers la table enfant mais sans participer à sa clé primaire.
- Informative, définit l'existence d'une relation mais sans déterminer une clé étrangère.
- M-N, va automatiquement générer la création d'une table intermédiaire réalisant la relation.
Jusqu'ici j'ai toujours parlé d'une relation avec la clé primaire du parent mais il est également possible de faire une relation sur une clé secondaire ou sur un champ unique.
Il est aussi possible de créer une relation d'une table sur elle-même. Dans ce cas, vous ne pourrez évidemment pas choisir une relation de type identifiée.
VI-C. Module de vérification▲
A ce stade si nous utilisons le module de vérification du modèle, nous allons recevoir des "warning". En effet pour les tables sous SQL Server, nous devons définir un propriétaire (owner) pour chaque table (entité).
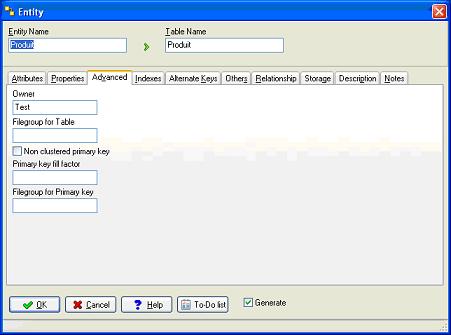
VI-D. Contraintes▲
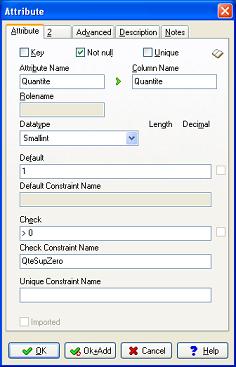
Outre les contraintes des relations déjà vues plus haut, il est possible de définir des contraintes sur les champs. Dans l'exemple ci-dessous, on définit une contrainte nommée "QteSupZero" qui impose un nombre supérieur à zéro.
VI-E. Génération du script▲
Nous pouvons maintenant passer à la génération automatique du script.
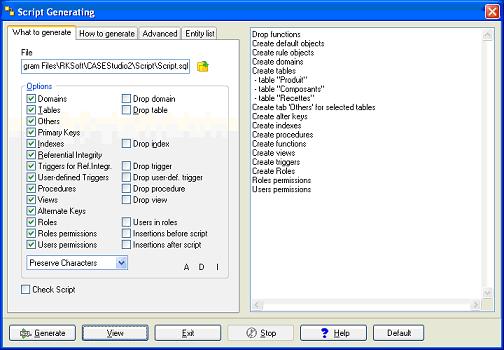
Voyons à quoi ressemble le script généré.
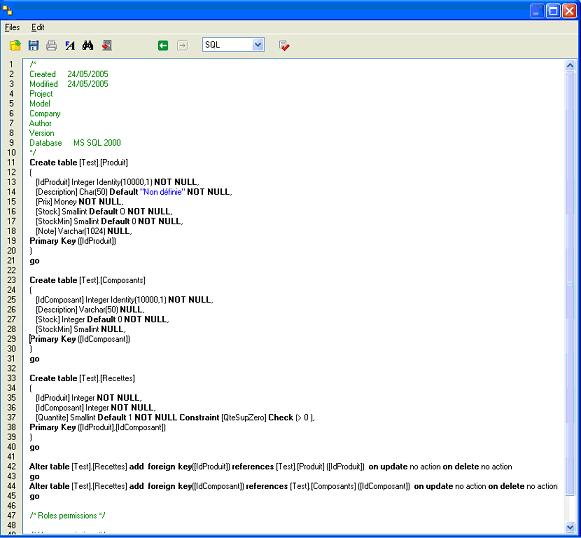
Le script peut être directement modifié dans le viewer et ensuite enregistré pour un usage ultérieur. Les commentaires sont automatiquement complétés grâce aux propriétés du modèle.
VI-F. Conversion vers un autre gestionnaire de base de données▲
Si vous souhaitez changer de gestionnaire de base de données, le logiciel vous fournit un module de conversion.
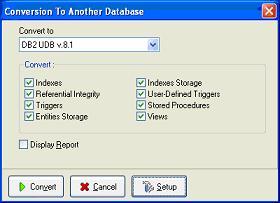
Le setup permet de modifier la conversion des types de données.
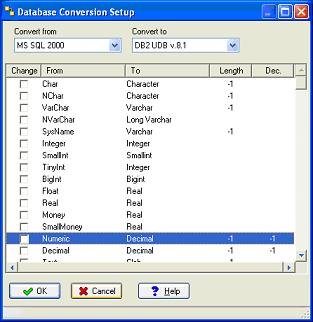
Dans notre exemple, je fais la conversion de MS-SQL vers DB2. Si nous générons le script, il donne maintenant :
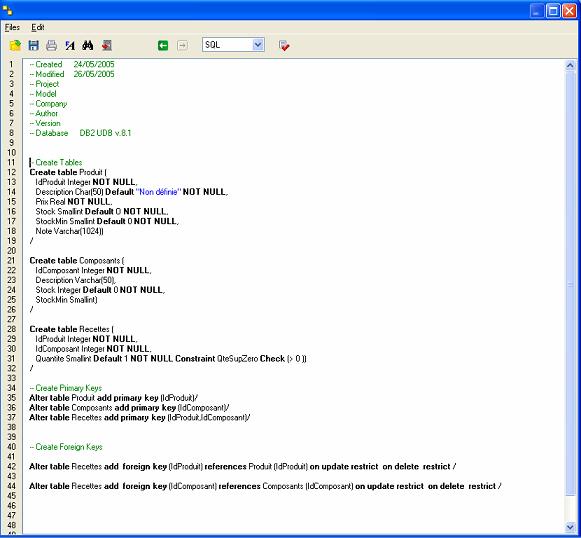
Le script a clairement été adapté pour refléter la syntaxe DB2. Il faut tout de même faire attention aux fonctions spéciales. Si nous regardons l'onglet "Advanced" du champ "IdProduit", nous voyons que la valeur initiale de l'autonumber n'est plus 10000 mais 1 ! En fait rien de bien étonnant puisque la gestion de ce type de champs est différente d'une base à l'autre. C'est en fait le résultat du choix de l'éditeur d'offrir les options les plus poussées relatives à un gestionnaire de base de données. S'il avait pris l'option de rester plus générique, l'écueil aurait pu être évité. Pour ma part, je suis favorable à l'option de l'éditeur dans la mesure où l'on change rarement de gestionnaire de base de données mais cependant il peut être intéressant de disposer des options avancées qui ne pourraient pas être présentes dans un modèle générique.
VI-G. Vues, Procédures stockées, trigger, ...▲
Différents objets peuvent également être ajouté aux modèles. Il s'agit d'objet de type texte. Cette option est disponible dans le menu modèle.
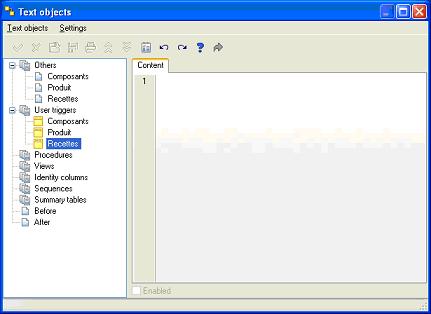
Par exemple, pour ajouter une vue, il suffit de cliquer sur "Views" avec le bouton droit et de choisir "Add". Vous donnez un nom, vous tapez votre code dans la partie droite de l'écran et vous cliquez sur "Ok" dans le menu ou sur le bouton équivalent dans la barre d'outils et la vue est ajoutée.
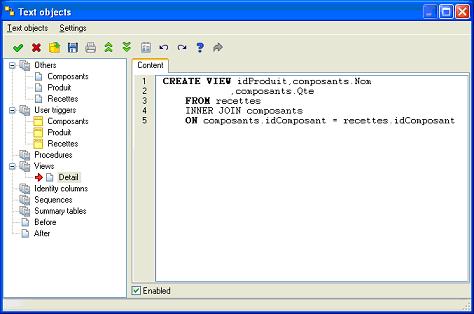
Pour vous faciliter le travail, il est possible d'utiliser un "pattern".
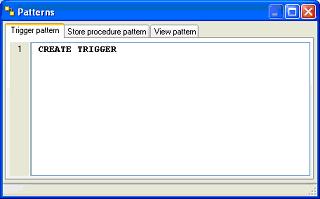
Pour un trigger, il faut cliquer avec le bouton droit sur la table sous l'option "trigger" et choisir "Add trigger". Il suffit alors de procéder comme pour la vue.
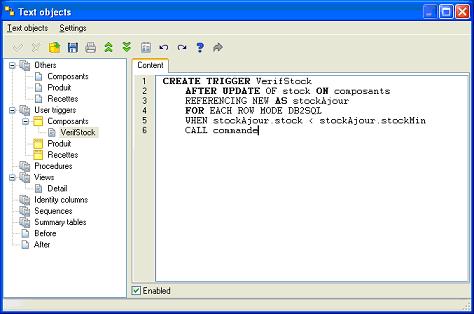
Le code sera évidemment ajouté lors de la génération du script. Bien sûr cette partie ne bénéficie d'aucune conversion en cas de changement de gestionnaire de base de données.
VI-H. Les types utilisateurs.▲
Il est également possible de définir vos propres types de données. Cette fonctionnalité est disponible depuis le menu "Dictionary"
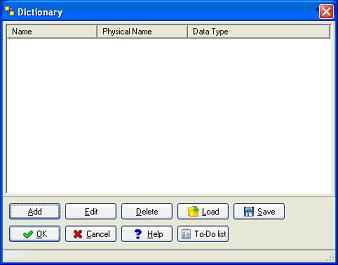
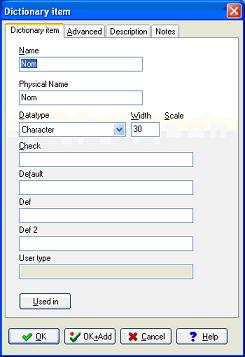
Le type ainsi défini est alors disponible lors de la définition des champs des tables et donne lieu à l'écriture du code nécessaire lors de la génération du script.
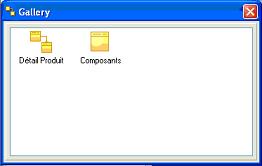
VI-I. La galerie.▲
La galerie permet de stocker des tables ou des extraits de schéma qui pourront alors être réutilisés par simple copier, coller. Cette fonction est très utile pour augmenter la productivité car nous avons tous des tables qui sont régulièrement utilisées. Pour ajouter un élément à la galerie, il suffit de sélectionner la partie voulue dans le graphique et via le clique sur bouton droit, de choisir "Add to gallery" Pour les réutiliser, il suffit ensuite de faire un drag&drop.
VI-J. Sous modèles.▲
Il est possible pour des projets travaillant sur un grand nombre de tables, de créer des sous modèles. Cela permet de simplifier le travail et la vision du diagramme.
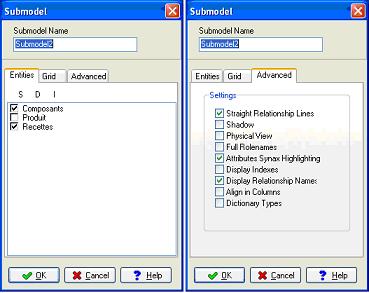
Après avoir créé votre sous modèle, vous pouvez choisir d'afficher uniquement le sous modèle ou le diagramme en entier. Vous pouvez choisir pour le diagramme de n'afficher que les entités (avec ou sans les clés) et pour le sous modèle d'afficher un maximum d'information. Le diagramme général est ainsi nettement simplifié. Ceci est rendu facile car Case studio conserve le paramètre d'affichage pour chacun des modèles. On peut regretter que les concepteurs n'aient pas poussé l'idée jusqu'à permettre l'affichage des sous modèle comme une entité particulière dans le diagramme général.
VI-K. Informations complémentaires dans le diagramme.▲
Il est possible d'introduire une étiquette reprenant les données du modèle mais également d'inclure des notes.
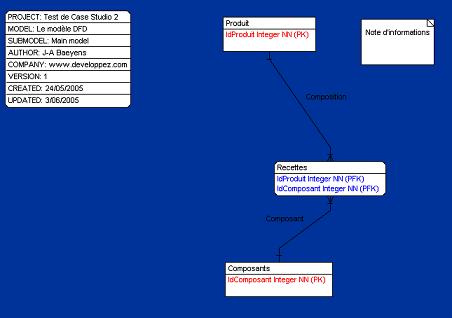
Il est dommage que les notes ainsi introduites ne puissent être liées visuellement à un des composants du diagramme. De même, il n'y a pas de possibilité d'afficher sous cette forme les notes introduites au niveau des différents composants du modèle. Une option sous forme d'une case à cocher aurait pu être prévue à cet effet.